

¿Cómo puedo ayudarte?
Mi nombre es José Luis Maturana y soy bioinformático. Mi intención es ayudar en proyectos bioinfomáticos en general.
El campo de la bioinformática es amplio y es frecuente que existan múltiples opciones para analizar un tipo de datos en particular. Lo importante es realizar una selección informada de los métodos de análisis y así definir un pipeline de trabajo adecuado. Mi objetivo es tratar maximizar la información extraída de los datos, siempre considerando que son datos de origen biológico.

Buenas prácticas

La elección de los programas utilizados siempre tomará en cuenta la tecnología utilizada para la obtención de los datos y siempre se llevan a cabo controles de calidad.
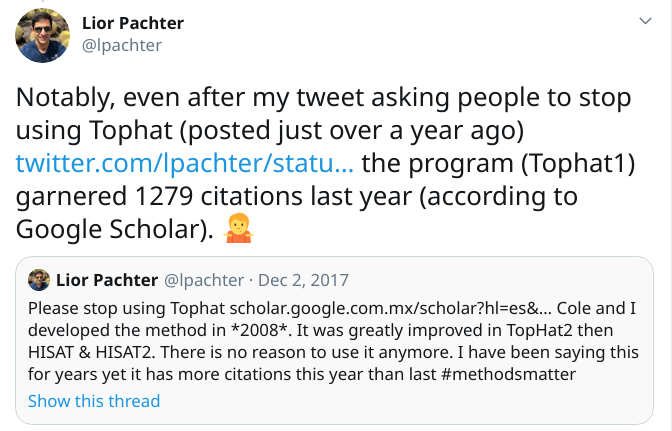
No usar software simplemente porque es popular. Atención a sus versiones y a las prácticas actuales en el campo del problema a resolver arrow_circle_down
Flujos de trabajo reproducibles. Esto quiere decir que un usuario con un conocimiento básico en informática, pueda ejecutar los programas y reproducir los resultados por sí mismo después de seguir un conjunto breve de instrucciones:
$ ejecutar instalacion-de-software
$ ejecutar pipeline-part1
$ ejecutar pipeline-part2
# analizar resultadosEsto se puede lograr de múltiples formas, ya sea con un script
“tradicional”, o
en el caso de pipelines más complejos, se puede utilizar snakemake arrow_circle_down
snakemake
es
una librería que permite desarrollar pipelines de trabajo
completos,
haciéndose cargo de instalar el software necesario para llevar a cabo
todos los pasos
definidos en éste. Entre otras cosas, es especialmente útil para
desarrollar flujos de
trabajo reproducibles. Tiene opciones que se acomodan a un clúster de
cómputo típico
de centros académicos (slurm u otros), pero además puede ser
utilizado en
cloud services como Amazon web services, Google
Cloud y
Microsoft Azure.
Informes que pueden contener elementos y visualizaciones interactivas: Esto es visualizaciones con las que se pueda interactuar a través de controles o reaccionen al input del usuario. La interactividad de las visualizaciones tiene un objetivo funcional. Según el contexto del problema, pueden hacer más eficiente el análisis de la información, pues ayuda a que un usuario que no produjo una visualización, explore los resultados de forma más simple, haciendo este proceso más rápido arrow_circle_down

Análisis disponibles
Aquí se listan análisis frecuentes en el área de la bioinformática y con los cuales he tenido experiencia, mas, puedo realizar análisis de datos “omicos” en general. Por ejemplo, aquí escribo sobre una opción para integrar múltiples datos “ómicos”, usualmente llamado meta-análisis.

RNA-Seq, conjunto de células (bulk) y single-cell.
Análisis de datos “ómicos” en general: Metilomas, marcas de histonas, accesibilidad a cromatina, etc.
Múltiple alineamiento y filogenias, Maximum Likelihood y Bayes.
Análisis de microbiomas
Proyectos de secuenciación en general:
Ensamblaje de genomas
Alineamiento de genomas y análisis de variantes genéticas.
Anotación de genomas, ya sea procariontes o eucariontes.